There are three methodologies for mapping Citations into a framework. Two are suitable and one is...

There are three methodologies for mapping Citations into a framework. Two are suitable and one is not suitable at all, but seems to persist.
The minimum mapping process
1. The process begins with “AD Cataloging” where a reference document is cataloged and entered into the system. This is the first step in the workflow.
2. Next, in the “Implementation Entry” step, the implementation requirement is inputted into the system, ensuring that all necessary details are captured accurately.
3. Following this, the “Implementation Tagging” step involves tagging the terms of the requirement. This step also includes separating the requirements for better clarity and organization.
4. In the “Dictionary” phase, a search for the term in question is conducted. If the term already exists and its definition matches the current context, the existing definition is selected. If the term exists but the definition does not match, or if the term does not exist at all, a new term and definition are created accordingly.
5. The “Matching” step involves searching for a requirement to control similarity. If no match exists, the requirement is ignored and the process is halted. However, if a match is found, the requirement is mapped to a reference control.
6. Finally, the “Audit” stage entails creating an audit question according to ABA standards. This marks the end of the process.
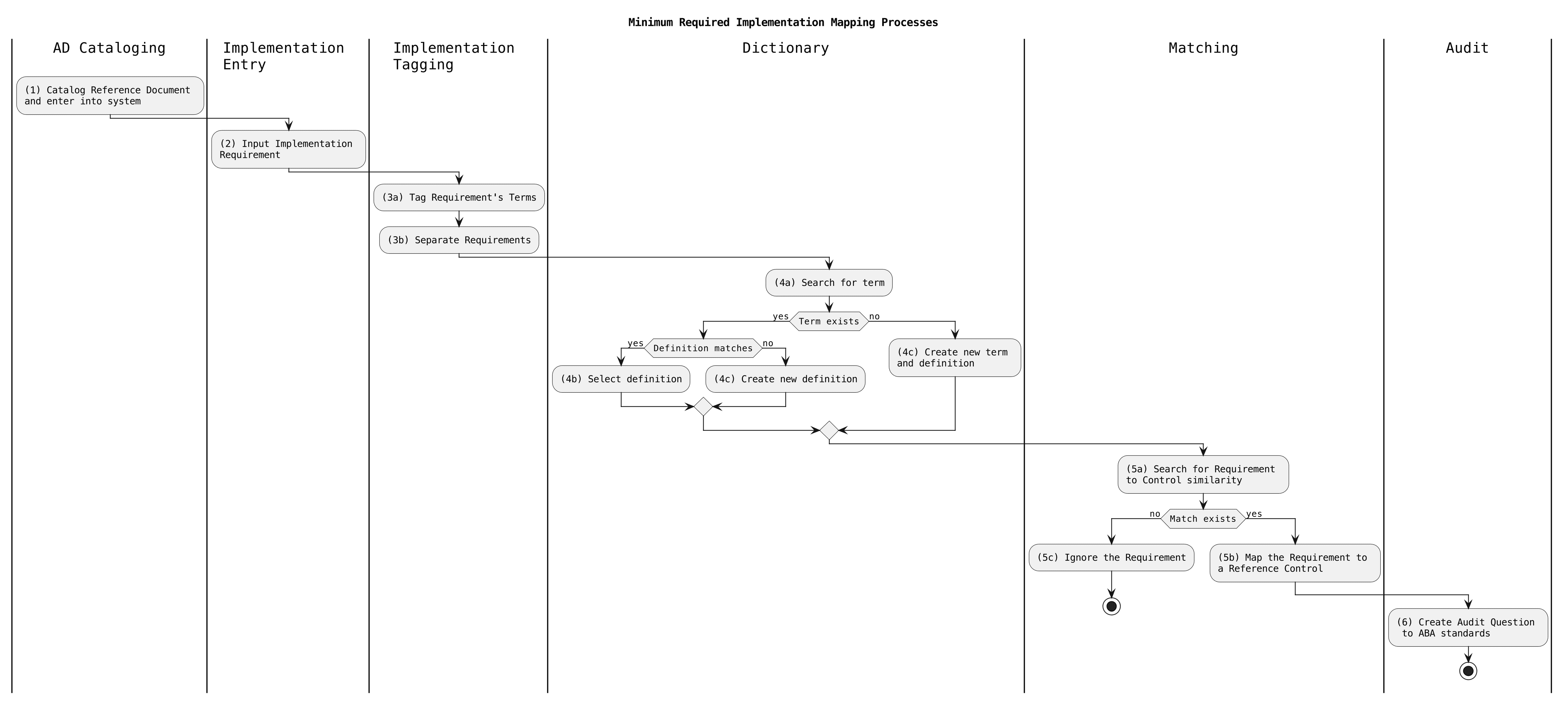
Each step is crucial in ensuring that the implementation requirements are accurately processed and recorded, adhering to the necessary standards and facilitating efficient auditing and control matching.
The UCF’s mapping process
The methodology above shows how the mapping is done from an Authority Document into a set framework. The methodology below shows how the mapping is done from an Authority Document into the Unified Compliance Framework. The difference is that the Unified Compliance Framework isn’t a static framework. It is a dynamic list of Common Controls derived from mandates found in Authority Document Citations.
0. We start with zero because we believe checking for the legality of mapping is paramount and the rest of the process can’t move forward without it. Therefore, the process starts with the “Issuer and Corpus” stage where the legality of text and data mining (TDM) is determined. If TDM is not legal, the process stops immediately. If legal, the URL is tagged for scraping and the document is added to the corpus.
1. In the “AD Cataloging” phase, a reference document is cataloged, and metadata are added to enhance the catalog’s utility and information depth.
2. Next, the “Citation Entry” step involves extracting citations and inputting them into the system. If the citation is deemed a stub or merely informational, it is marked accordingly and the process halts. If not, the process continues to the next stage.
3. The “Mandate Tagging” phase includes tagging the terms within the citation and separating the mandates for better clarity and categorization.
4. During the “Dictionary” step, a term search is conducted. If the term exists and its definition matches the current need, that definition is selected. If the term exists but the definition does not match, or if the term does not exist, a new or updated definition is created and advanced semantic relationships are added. This stage also involves linking terms and mandates to implementation methods such as records and assets.
5. In the “Matching” step, a search for mandate similarity is carried out. If a match exists, the mandate is mapped to a common control and the process stops. If no match is found, the process transitions to “Control Creation” where the mandate is transformed into a common control. The mandate’s readability is evaluated and simplified to at least a B+ grade before placing the common control into a hierarchical structure.
6. Finally, the “Audit” stage involves creating an audit question in accordance with ABA standards, marking the end of the process.
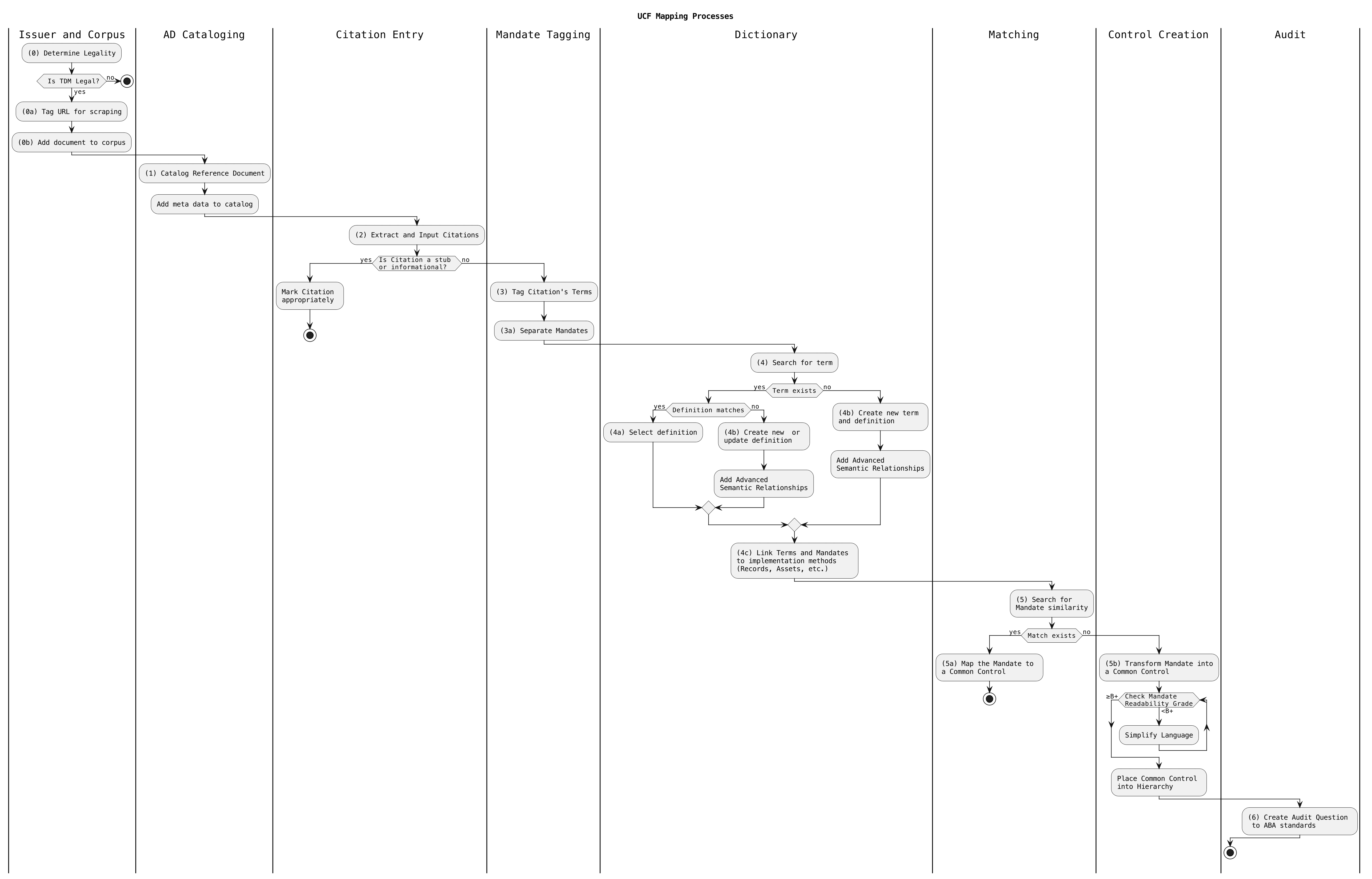
Each step ensures that the documents and data are legally and effectively integrated into the system, providing a robust framework for compliance and control.
The differences between these two approaches
The differences start with content tagging in step 3. UCF’s approach uses its vast suite of tagging patents and dictionary patents to properly define predicates and subjects whether they are single terms or multiword expressions.
This allows the term search in step 4 to be more robust with the UCF method – advanced semantic relationships being a patented UCF process.
Step 5 is the biggest difference between the two. In the static system (such as mapping from an Authority Document to PCI, or NIST) requirements without a match are ignored. With the UCF’s dynamic Common Control creation process, new Common Controls are added to the framework when unique mandates are found.
More importantly, this mapping process supports AI-driven ingestion and API driven output methods such as the Intelligent Content Pipeline.
Then there’s the Drunken Zombie approach the SCF uses
We have it on good authority that the Secure Controls Framework uses Drunken Zombies to do their mapping. They’ve even gone so far as to hire someone who writes English (we’re positive drunken zombies can’t write) to post a document explaining why Natural Language Processing is “bad”1. It is our firm belief that the SCF and a few others that employ drunken zombies follow the following process when mapping compliance. The process humorously (what else can you do but laugh, huh?) outlines a series of steps for dealing with documents in a rather unconventional manner, reflecting a zombie-themed, relaxed approach.
1. The process begins in the “AD Cataloging” stage, where a link to the reference document is created and added to a spreadsheet. This ensures that all documents are organized and easily accessible.
2. Next, the “Citation/Implementation Entry” phase involves reading citations or implementation requirements to understand the content that needs to be handled.
3. For harmonization, the “Mandate Tagging” stage entails guessing what the mandates are within the document.
4. In an amusing departure from typical procedures, the “Dictionary” stage instructs to take a break and humorously suggests eating someone’s brains, implying no actual work is done in this phase.
5. The “Matching” step involves guessing at the similarity between mandates and implementation requirements. If no match exists, the mandate or implementation requirement is ignored, and the process is stopped. If a match is found, the next step is to map the mandate or implementation requirement to a reference control.
6. Finally, in the “Audit” stage, an audit question is created to zombie standards, marked by the nonsensical phrase “only if zurn blork,” (hey, that’s what the Zombies we talked to told us) suggesting a lighthearted and whimsical approach to compliance. The process concludes after this step.
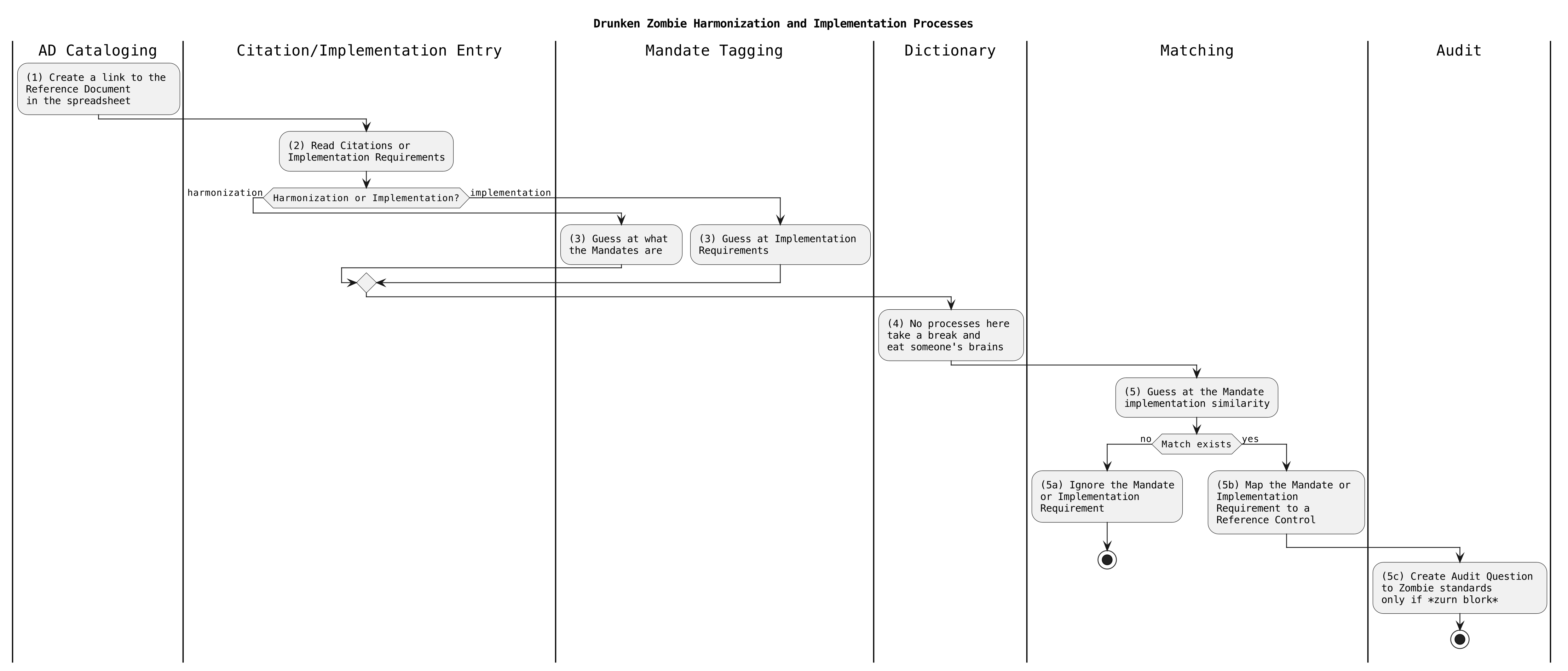
Overall, this document uses a playful and fictional setup to describe a process workflow, focusing more on humor than on practical application.
Seriously though…
We poke fun of the drunken zombies over at SCF, well, because drunken zombies are funny.
But they are also terrifying if you take them seriously.
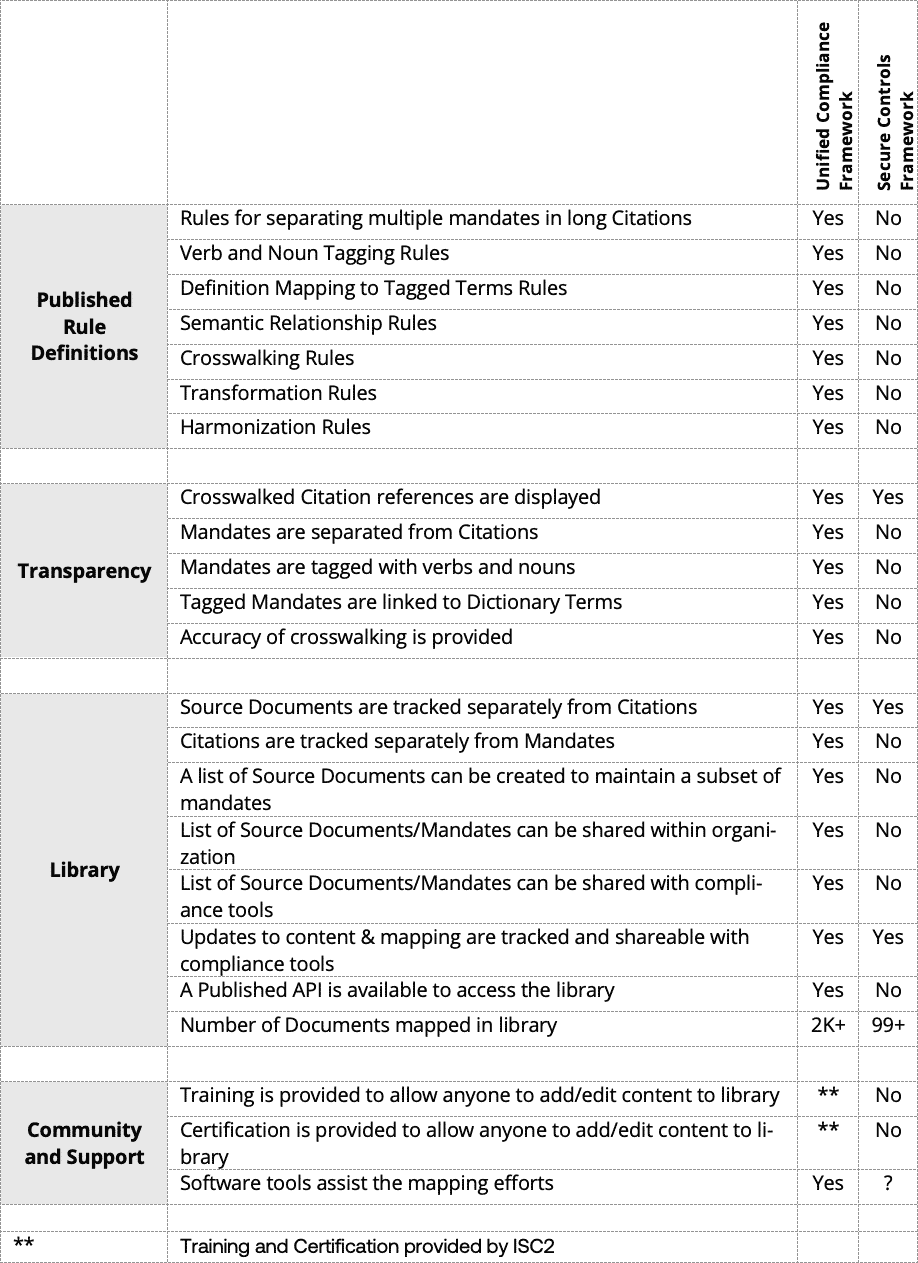
Folks, they create a spreadsheet. They don’t have a JSON structure2. They believe AI patents don’t hold up to the Patent Office standards (even though we were awarded yet another AI-related patent in 2024)3.
-
See their blog post on “Set Theory Relationship Mapping.” By the way guys, our lawyers think you need better lawyers. The case you quoted doesn’t fit, and the US and foreign patent offices feel pretty strongly that our couple hundred patent claims are insurmountable. ↩︎
-
At least they told our lawyers they don’t… ↩︎
-
https://securecontrolsframework.com/set-theory-relationship-mapping-strm/ ↩︎